
Server-side experiments
Server-side experiments is a form of A/B testing experimentation in which the variations of a test are rendered directly on the web server, before it is delivered to the client. This is distinguished from client-side testing, where the A/B test is rendered on the client-side through JavaScript after the page is delivered to the user’s browser.
| Category | Description |
|---|---|
| Overview | Uses REST API as the method of testing site content. All dynamic action is taken server-side. |
| Where does content get changed? | On the server, before the page is rendered. |
| Advantages | - Faster page load, without re-rendering - More developer control - Integrates well with proprietary frameworks - Increased data security – sensitive data does not need to be stored client-side |
| Disadvantages | - Requires higher technical involvement - Longer implementation period - Can be harder for business stakeholders to use |
| Examples | - Major structural changes to the page - Full-page redirects - Secure access to back-end systems (pricing models, real-time inventory) - Pre-render experiment of Single Page Apps |
In pure server-side integration, your server securely interacts with an API Gateway, passing the page request details and asking for relevant variants for the experiment.
The response is typically a JSON payload. The caller is responsible for parsing the response and acting on it.
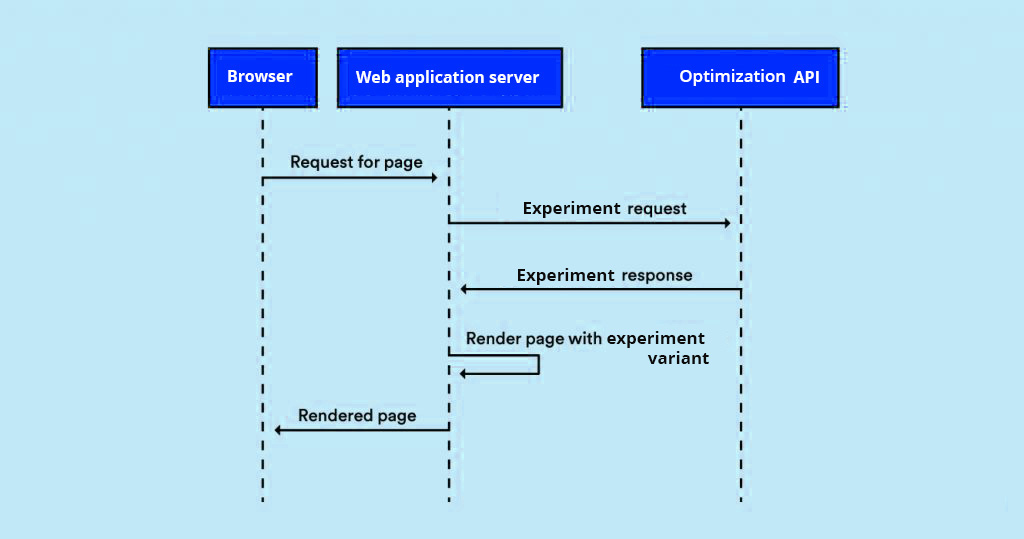
When to use server-side experiments
Since modern web applications have become more dynamic and technically complicated, testing within these applications has also become more complex. Server-side testing can handle this increased complexity. Instead of being limited to testing headlines or button colors on your website, you can test more impactful variations, such as algorithms, architectures, and other non-UI changes like a database query result set.
Thus, server-side testing is frequently the choice of product development teams who want to run complex experiments that explore how a product works, as opposed to the client-side conversion rate testing popular with marketing teams.
Prerequisites
The main things you need to make sure of to start your server-side experiments are:
- You have developer resources to work with.
- You're in an area served by one of our data centers.
- If you work with a CDN, ensure you can deliver dynamic content (vs. fully cached, static pages).
Key concepts
- Server-side experiment. Refers to an approach in A/B testing where the experimental logic is handled on the server rather than the client (e.g., web browser or mobile app). This method allows for more robust, secure, and versatile testing of application features or changes that impact the backend functionality or have significant implications for the system's performance and user experience.
- Control . Represents the current state of affairs—the “business as usual” or the standard user experience, without any new changes applied. It’s what you measure new variants against to understand the impact of the changes you are testing.
- A Variant is a product or feature experience being tested, often by assigning values to control variables. In simple A/B experiments, A and B are two variants, usually called Control and Treatment.
- Statistical Significance can be assessed using multiple approaches. Two of these approaches are using the p-value and the confidence interval:
Creating a server-side experiment
To create a server-side experiment, go to Server-side experiments > Create server-side experiment
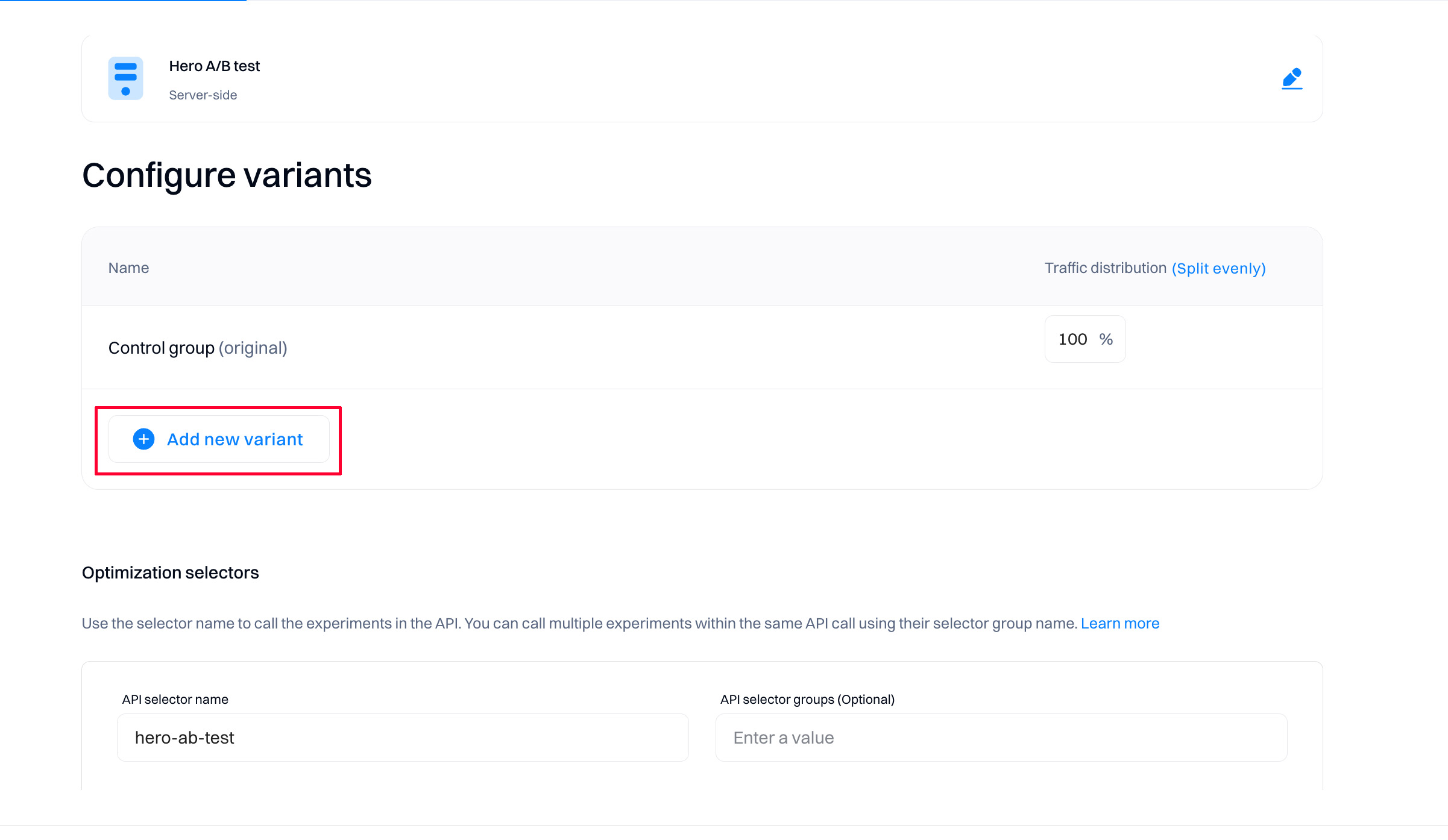
Create a variant
You must create the first variant you would be testing in your experiment. To proceed, select "Add new variant."
Good to know
In experiments, control is always addded by default. Note that control groupd is the original, unchanged website or app experience primarily used to evalue the statistical significance of your experiment.
When you add a new variant, you can select whether to create it from scratch or use an existing template (if it was created before).
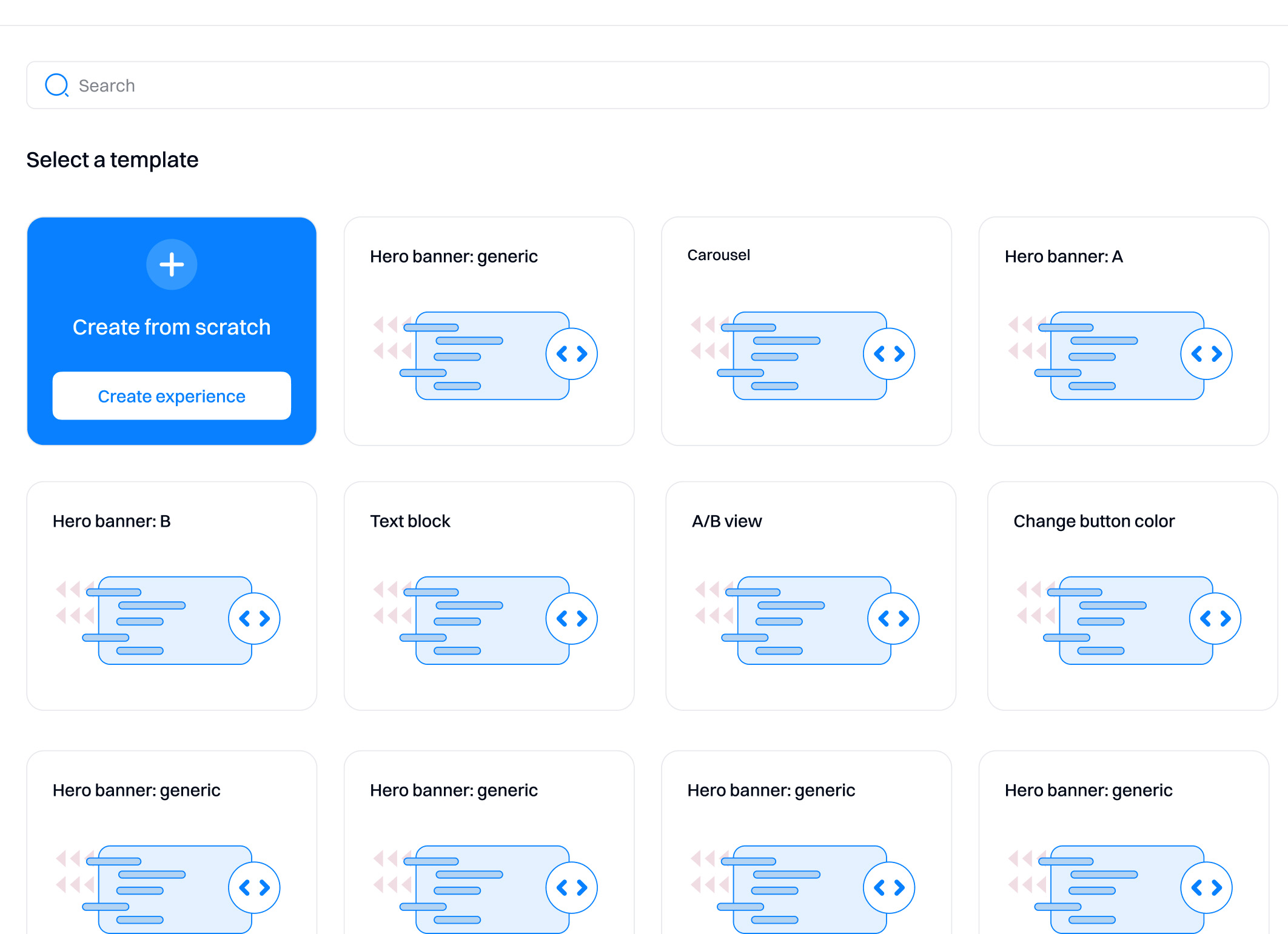
- Create from scratch. Create your variation from scratch using custom JSON payload. When you click this option, the Intempt code editor is displayed. After you enter your custom code, you can save it as a template and reuse it by clicking "Save as Template."
- Templates. These are templates you created and saved in your project.
Creating from scratch
You need to enter the JSON payload of the variant to be sent when the experiment is served. This requires you to have access to your website or app's code to create different variations based on the existing codebase. Intempt will replace specific sections of your website (or add new ones) by sending the payload you enter within the code editor.
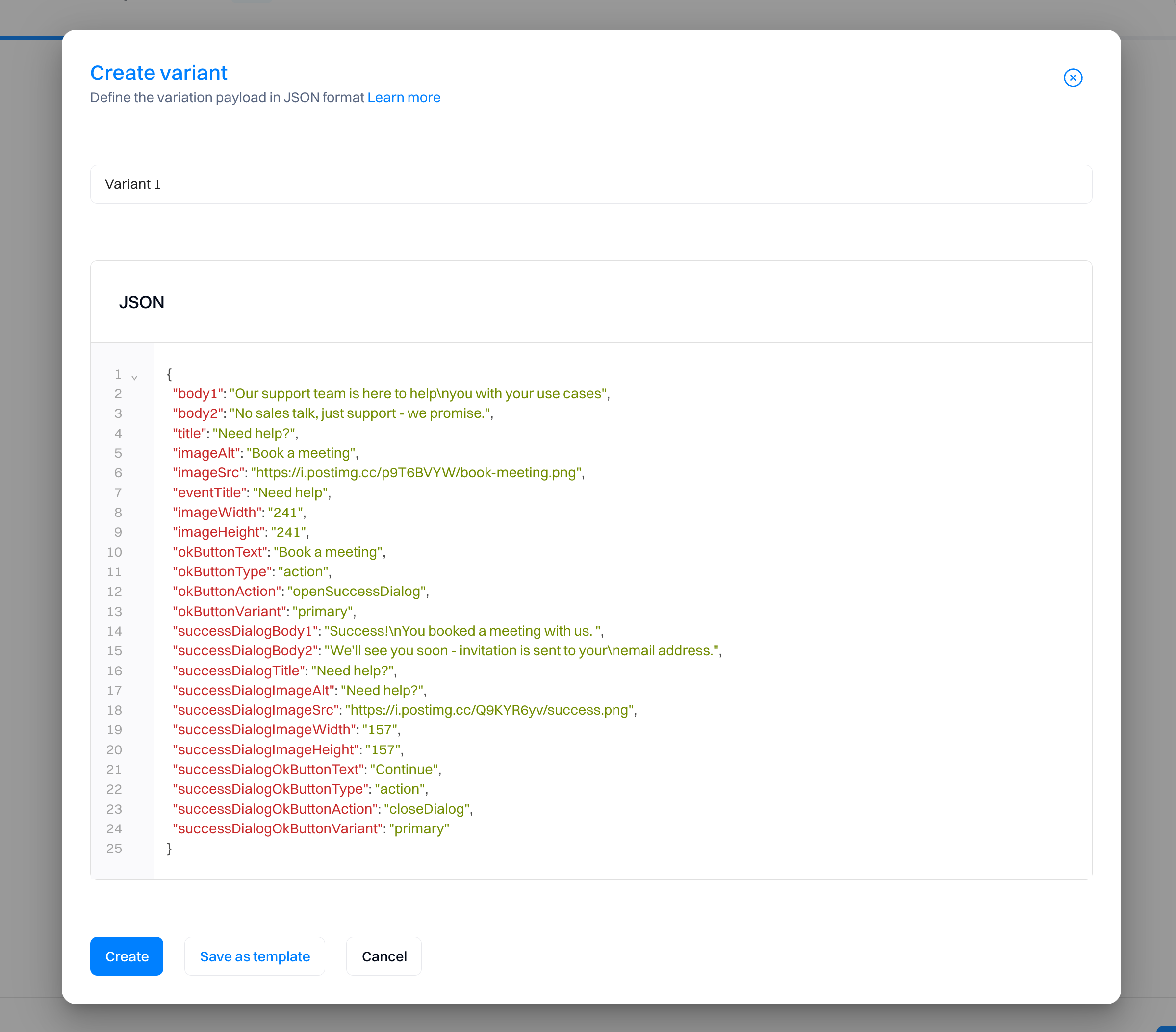
Good to know
A JSON payload in the context of server-side experiments is essentially a block of structured data. JSON (JavaScript Object Notation) is a lightweight data-interchange format, which is easy for humans to read and write, and easy for machines to parse and generate. In server-side experiments, these JSON payloads define different experiences or variations of content that might be displayed to a user.
For example, if you want to have a variant that shows a popup in your app:
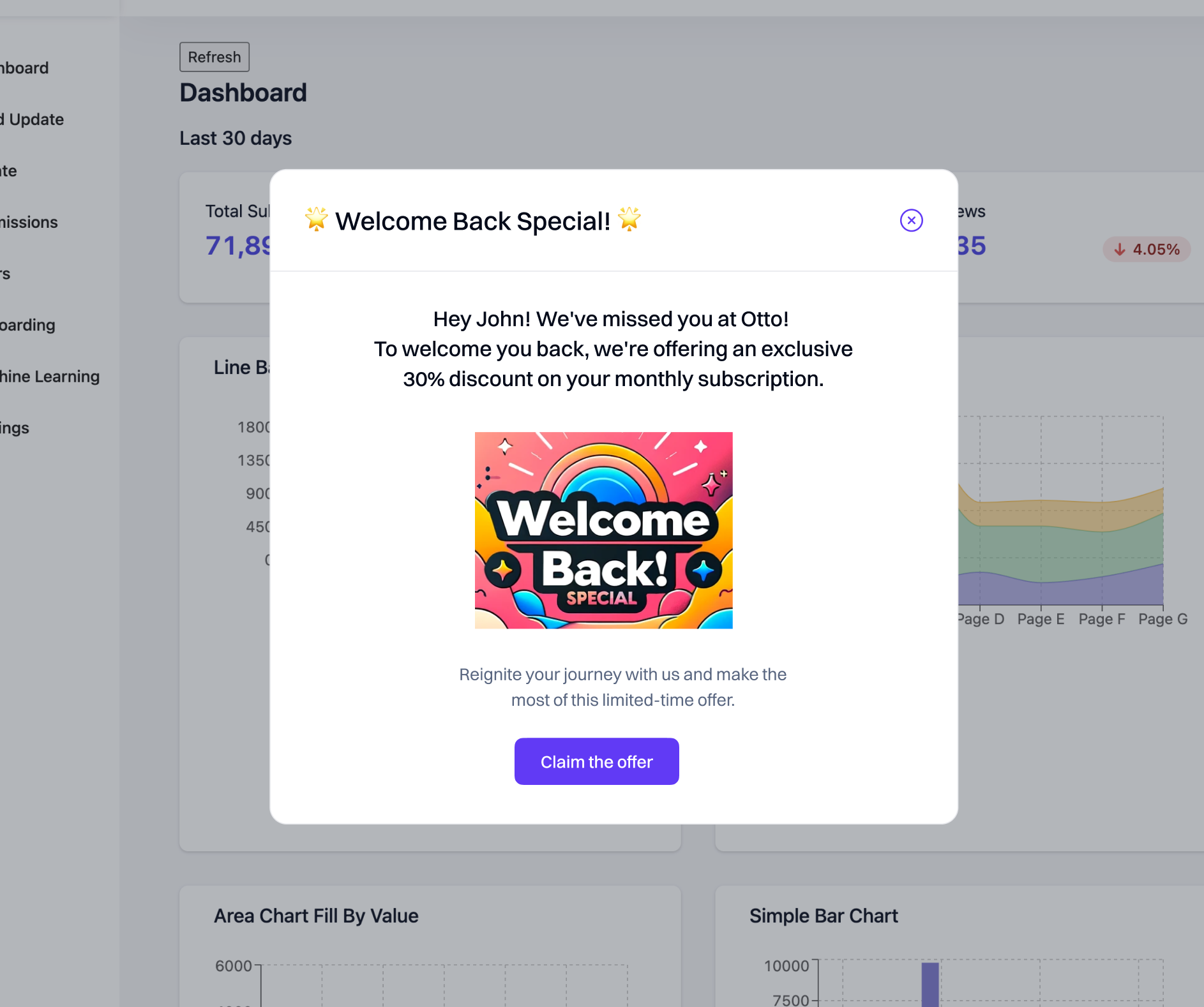
You would need to use this JSON payload.
{
"body2": "Reignite your journey with us and make the\nmost of this limited-time offer.",
"title": "🌟 Welcome Back Special! 🌟",
"imageAlt": "Claim the offer",
"imageSrc": "https://i.postimg.cc/7b7Q9W72/claim-the-offer.png",
"eventTitle": "Welcome back",
"imageWidth": "241",
"imageHeight": "184",
"okButtonText": "Claim the offer",
"okButtonType": "action",
"preImageBody1": "Hey {{ attribute.user.first_name }}! We've missed you at Otto!\nTo welcome you back, we're offering an exclusive 30%\ndiscount on your monthly subscription.",
"okButtonAction": "openSuccessDialog",
"okButtonVariant": "primary",
"successDialogBody1": "Success!\nThe discount is applied to your subscription",
"successDialogBody2": "Your next month subscription will have a 30%\ndiscount applied",
"successDialogTitle": "🌟 Welcome Back Special! 🌟",
"successDialogImageAlt": "Welcome Back Special!",
"successDialogImageSrc": "https://i.postimg.cc/Q9KYR6yv/success.png",
"successDialogImageWidth": "157",
"successDialogImageHeight": "157",
"successDialogOkButtonText": "Continue",
"successDialogOkButtonType": "action",
"successDialogOkButtonAction": "closeDialog",
"successDialogOkButtonVariant": "primary"
}
For this to work, you must use Optimization API to call Intempt APIs. These will serve the dynamic payload based on the specified targeting conditions, triggering the content on your site or app to load.
Creating from a template
If you select to create from a template, you can re-use and edit saved JSON payloads for accelerated setup.
To create a new template, you can save any existing variant by selecting "Save as a template." The template will then be available to select from the creation screen.
Set the Optimization selectors
To fully set the server-side experiment, specify the API Selector needed in Optimization API calls to activate one or more experiments (or personalizations) by name. The activation automatically resolves to target rules and group allocations and returns the correct user variant. Typically, you would make this call as part of your larger page and content rendering pipeline. The experiment settings are all controlled in the Intempt console.
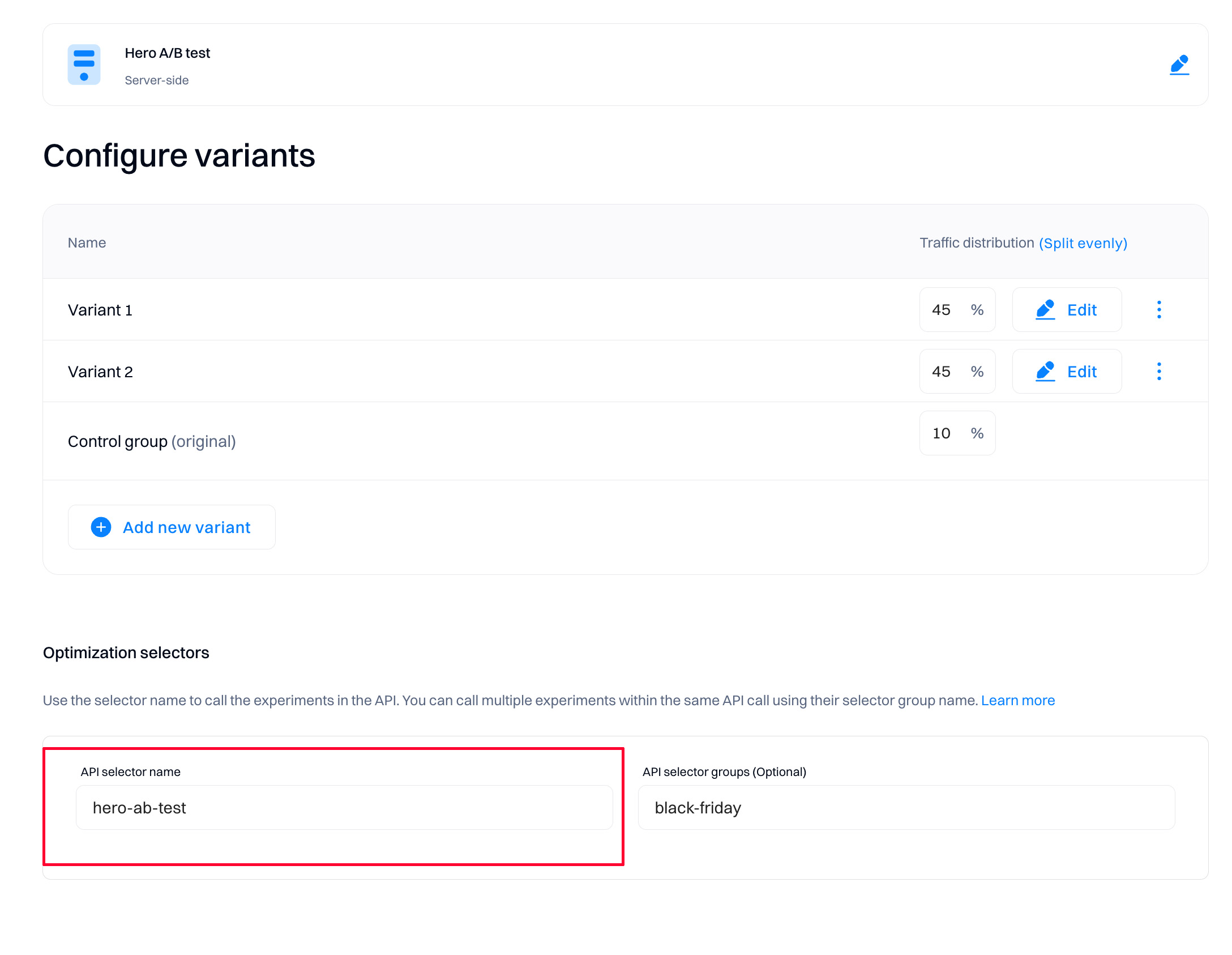
Good to know
The initial API selector name is auto-created based on the experiment name. You can change it at any time based on your requirements.
Set the Optimization selector groups (optional)
You can group and apply the grouping in your chosen calls to streamline the process of calling specific server-side experiments (or personalizations). Your developers can refer to a static Optimization selector group without worrying about changes made to a specific experiment's selector name. All the active selectors in the group are sent back in response to your chosen call, enabling you to call relevant experiments using their correct selector names as usual.
Good to know
Selector groups only allow entering values without spaces (use "-,_" seperators). Note that special characters like "*,/+=" are not supported
Optimization selector groups are defined and assigned in the Intempt console, and you can see which experiment is assigned to which group on the experiment page.
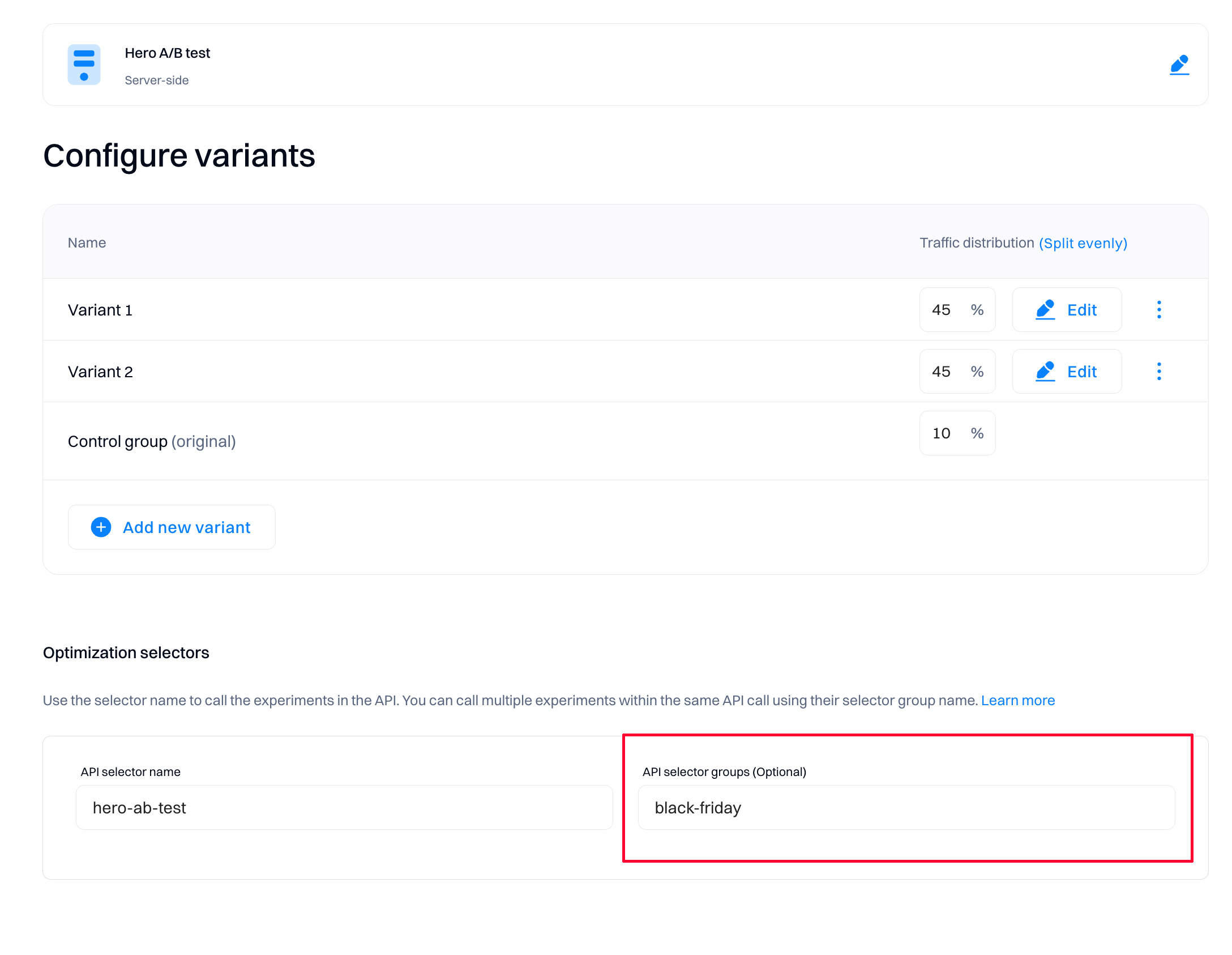
How is the content replaced on the website or app?
- Data Delivery: Once the appropriate JSON payload is selected, it is sent from the server to the user’s browser or app. This is typically done through an API call.
- Reading the JSON: The client-side of the website or app (the part running in the user’s browser or on their device) reads the JSON payload.
- Dynamic Content Replacement: Scripting on the client-side then dynamically modifies the HTML or app content based on the data in the JSON payload. For example, if the payload includes a different headline or a promotional banner, the script finds the relevant part of the current page or app view and replaces it with the new content specified in the JSON.
Configure traffic distribution
Traffic distribution means the proportion of traffic sent to a particular variation.
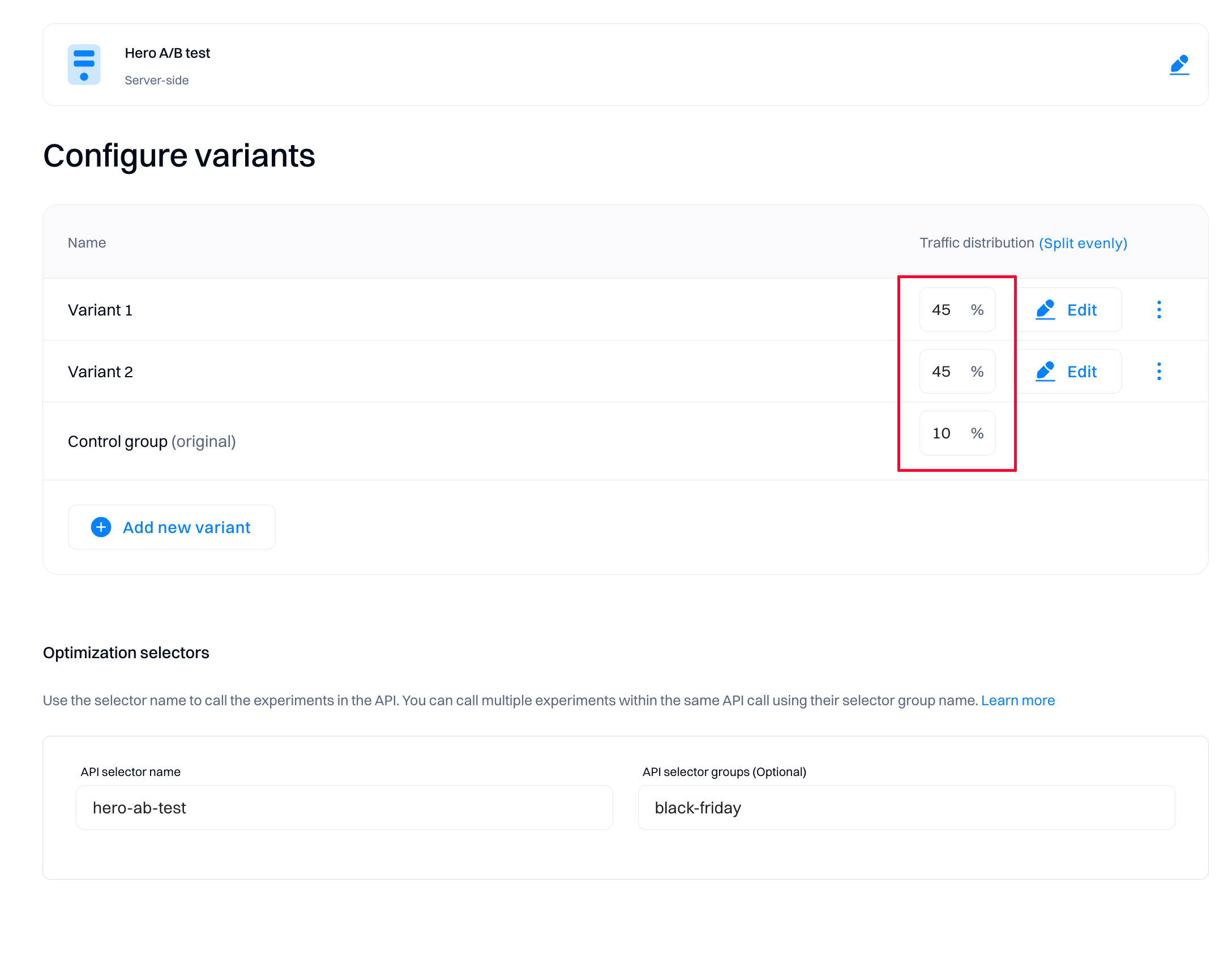
You can adjust the percentage of traffic bucketed into a particular variation. For example, if you have four variations and the traffic is distributed equally, each new visitor has a 25% chance of being placed into each variation.
Changes to traffic distribution affect only new users. Existing users (whether they were bucketed in a variation) keep seeing the same variation, even after you change traffic distribution. Users who are excluded from the experiment are always excluded.
However, stopping variations completely can potentially affect all users. If, for example, you stop a variation in an experiment, returning visitors who were previously bucketed into an experiment cannot see the variation to which they had been assigned and instead get the same variant as everyone else.
Good to know
The sum of traffic distribution always need to be equal to 100% for the experiment to be created correctly.
Configure the experiment scorecard
When running an experiment, it is common to try to test an explicit hypothesis, which you are measuring using a set of key metrics. The scorecard makes this easy, with the ability to enter your hypothesis and primary and secondary metrics.
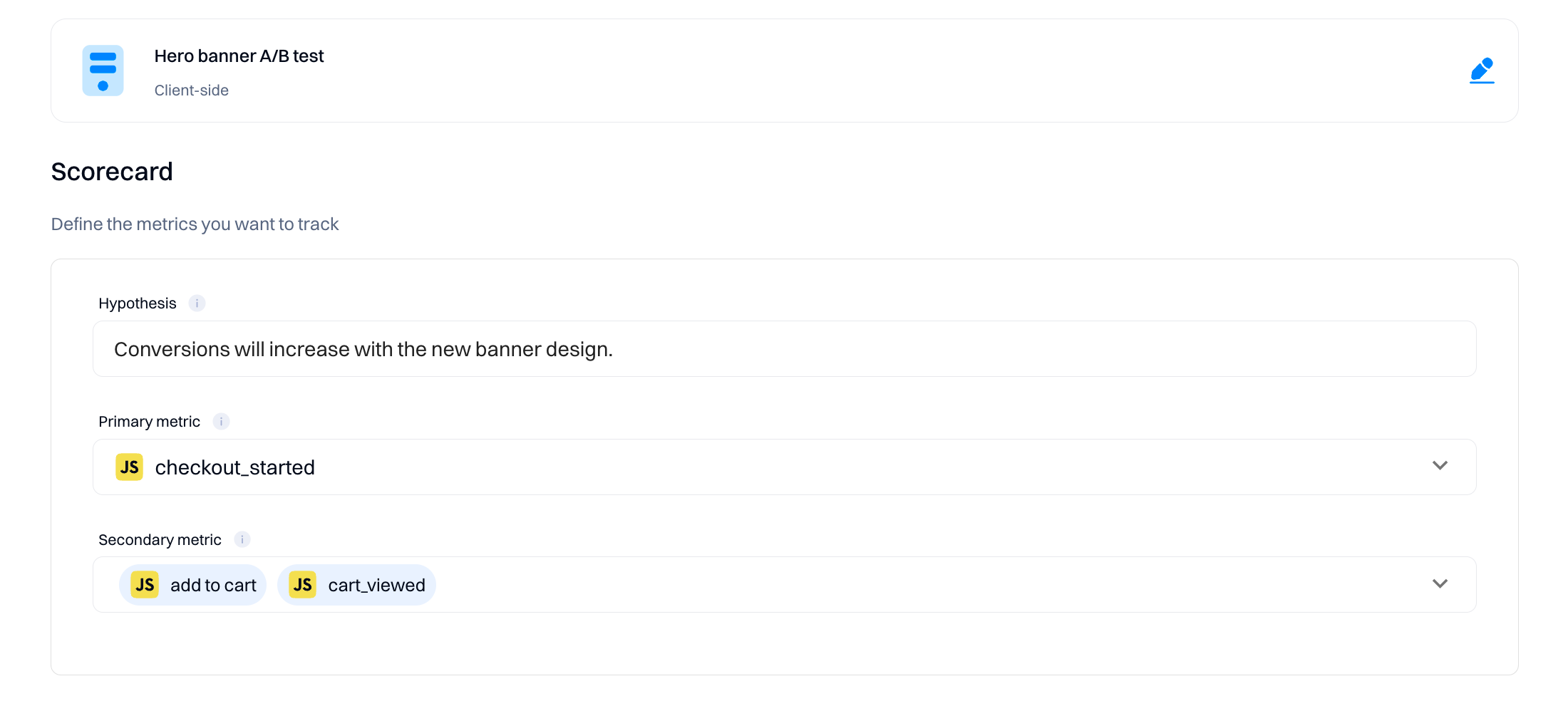
Primary metrics are the metrics you want to influence directly with your experiment. Secondary metrics are those you may want to monitor or ensure don't regress with your test but aren't directly trying to move.
Configuring the scorecard is optional but especially helpful to ensure that other team members viewing your experiment have context on the hypothesis being tested and how success is measured. Additionally, all metrics added to the Scorecard are pre-computed daily and eligible for more advanced statistical treatments like CUPED and Sequential Testing.
Configure the statistical setup
The statistical setup is the basis for determining the results of your experiments—all metrics will be calculated based on this configuration.
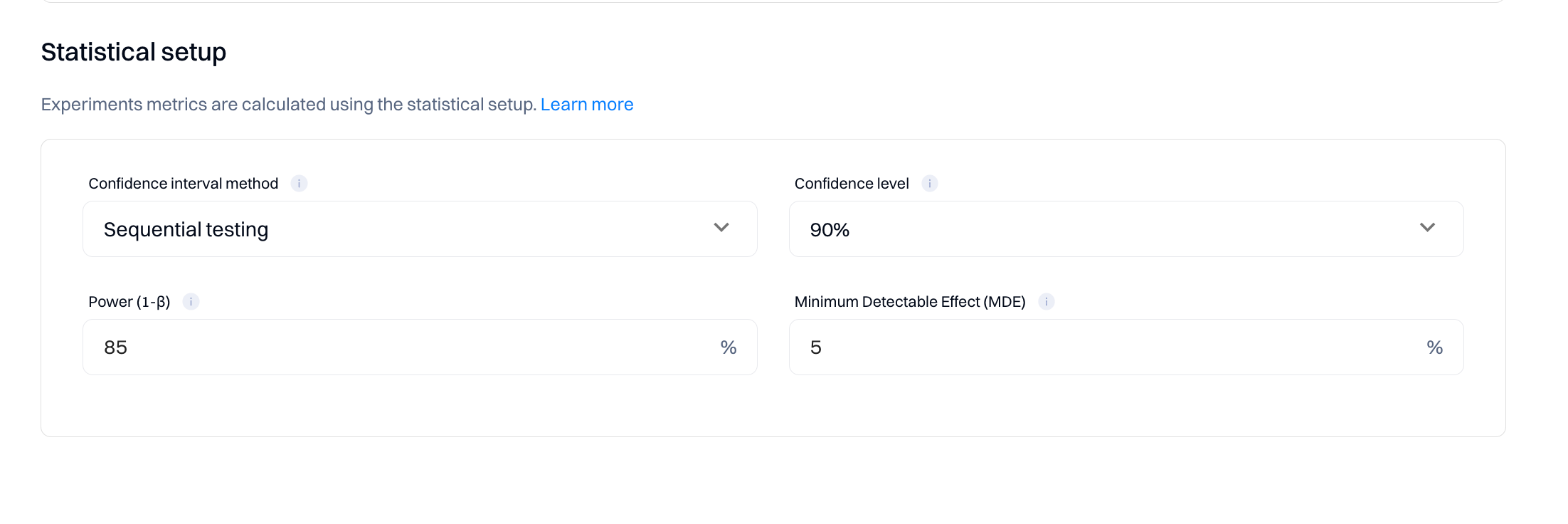
Refer to the following explanations when updating the default values.
1. Confidence Interval Method
In A/B testing, selecting the right confidence interval method is crucial for accurately analyzing your experiments. Intempt offers two methods: "Sequential testing" and "Sequential testing with CUPED variance reduction."
Sequential Testing
Sequential testing is a method used to evaluate the results of an experiment as the data comes in rather than waiting until the end of the test period. This approach allows for early stopping either for success if a significant result is detected or for futility if it becomes clear that continuing the test is unlikely to yield useful information. It contrasts with Bayesian tests, which calculate the probability of one variant being better than another at any point, allowing continuous monitoring without a fixed sample size. Sequential testing, however, relies on predefined rules for stopping, which can make it more structured but potentially less flexible than Bayesian approaches.
Sequential Testing with CUPED Variance Reduction
CUPED, which stands for Controlled-experiment Using Pre-Experiment Data, is a technique that reduces variance in your experimental data. By adjusting the observed outcomes using data collected before the experiment (like historical user behavior), CUPED can improve the efficiency of sequential testing by making it easier to detect true effects from the noise. This method is especially useful when dealing with high-variance metrics or when aiming to achieve results with fewer subjects.
2. Power (1-β)
Power, or 1-β, is a statistical measure representing the probability that your experiment will correctly reject a false null hypothesis (i.e., detect a real effect when it exists). In simpler terms, it's the likelihood that if your variant has a true impact, your test will pick it up. For Intempt, you can set the power anywhere from 0% to 100%. Higher values indicate a greater probability of detecting true differences, reducing the risk of Type II errors (false negatives). Adjusting the power helps balance the sensitivity of your tests and resource allocation.
3. Confidence Level
The confidence level is the probability that the value of a parameter falls within a specified range of the true value. Intempt allows you to select from three confidence levels for your A/B tests:
- 90% Confidence Level: This level suggests there is a 90% chance that the confidence interval calculated from the test data includes the true effect. It's generally used for quicker, less critical decisions.
- 95% Confidence Level: This is the standard choice, offering a good balance between certainty and efficiency. It means there is a 95% chance that the confidence interval contains the true effect.
- 99% Confidence Level: Opt for this high level of confidence when decisions are highly impactful or costly. It provides a 99% assurance that the confidence interval includes the true effect, but requires larger sample sizes.
4. Minimum Detectable Effect (MDE)
The Minimum Detectable Effect (MDE) is the smallest effect size that your test is designed to detect reliably. In Intempt, you can set the MDE anywhere from 0% to 100%. This parameter is essential for determining the practical significance of your test outcomes. Setting a higher MDE can reduce the sample size required for your test but might miss smaller yet meaningful impacts. Conversely, a lower MDE increases the sensitivity of your test but may require more data and time to provide reliable results.
Choosing the right values for these parameters in your A/B tests with Intempt ensures that your experiments are both efficient and effective, providing reliable insights that drive informed decision-making.
Good to know
For more information about the statistical setup, go to the Statistical significance
Configure target audience
Depending on your test, you may want to show the experiment to all users or target specific ones based on your selected condition (e.g., location, affinity, etc.).
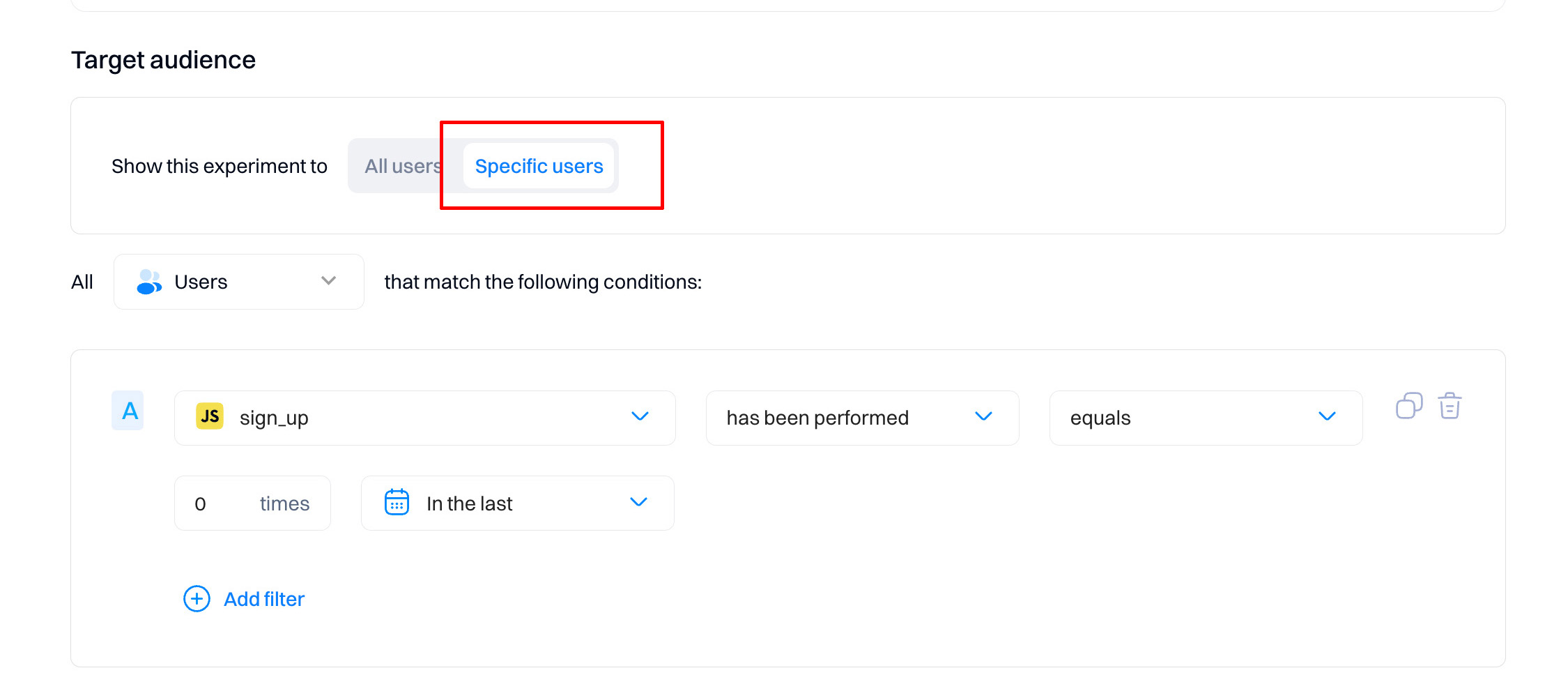
If you switch to "Specific users," you can use segment editor-like targeting options to add multiple conditions and filters.
Set the display options and target devices
"Display" refers to how frequently the variant will be displayed.
- Set "Always" if you want the variant displayed on each page load (if the user matches other conditions)
- Use "Once" to only allow the variant to be displayed for the user once per lifetime.
- "Once per visit" means that the variant will be displayed once per session

Target devices - define filters for devices that can render the experiment. Configuration depends on whether you want different targeting for mobile vs desktop users.

Start or schedule the experiment
When you reach the final step of creating your experiment in Intempt, you must decide when the experiment will begin. This section guides you through setting up the experiment start time.
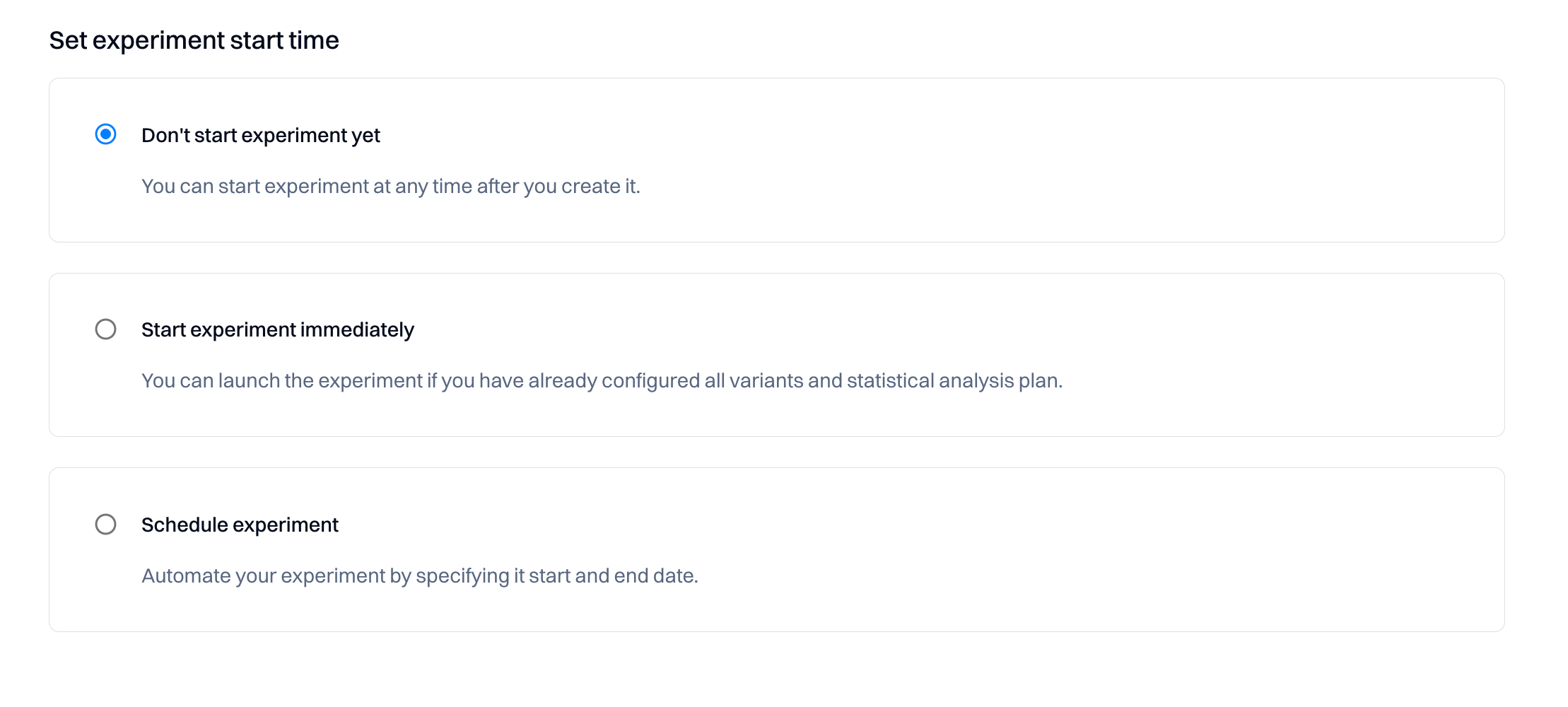
You have three start time options to choose from:
Option 1: Don't start experiment yet
- Description: Select this if you're not ready to launch the experiment immediately after creation.
- Usage: This option provides flexibility, allowing you to activate the experiment anytime post-creation.
- Instructions: choose this option if you wish to postpone the experiment's start.
Option 2: Start the experiment immediately
- Description: Opt for this if your experiment setup is complete and ready to go live.
- Usage: Ideal when all variants and the statistical plan are configured, and you're eager to collect data.
- Instructions: Select this radio button to initiate the experiment as soon as you conclude the setup process.
Option 3: Schedule experiment
- Description: Use this to automate the experiment's start and end based on a predetermined schedule.
- Usage: This is Perfect for aligning the experiment with specific dates or events or ensuring it runs within a defined timeframe.
- Instructions: specify the exact start and end dates after choosing this option.
How to set the start time
Follow these steps to set your preferred start time:
- Review the three options and decide which aligns with your experiment's requirements.
- Click the radio button adjacent to your chosen method.
- If you're scheduling the experiment, additional fields will appear to enter the start and end dates.
- Complete any remaining setup tasks and finalize your experiment configuration.
By selecting the appropriate start time option, you ensure that your experiment aligns with your project timeline and data collection goals.
Managing the experiment
Tabs overview
Tabs allow you to edit the experiment based on different sections.

- Results. View the experiment's performance —if it reaches statistical significance, you can make the decision.
- Variants. Create and edit variations and traffic distribution.
- Metrics. Configure the metrics that determine the results and the statistical setup.
- Targeting. Configure which users and devices will get the experiment and on which URLs.
How to start the experiment
You can start the experiment by selecting the "Start experiment" option. Alternatively, you can choose the "Schedule" option under the secondary "Save" button.

Experiment states
During the lifecycle of the experiment, the states will be updated based on the experiment's progress.

Draft
- Description: An experiment in 'Draft' is being prepared or edited. No data collection is occurring at this stage.
- Usage: Ideal for setting up the experiment's variables, hypotheses, and statistical models.
- Next Steps: Finalize the experiment's configurations and, when ready, move it to the 'Running' state to begin data collection.
Scheduled
- Description: The 'Scheduled' state is assigned to experiments with a planned future start date.
- Usage: Opt for this state if you want the experiment to commence automatically at a specific time.
- Next Steps: The experiment will automatically transition to 'Running' on the scheduled start date.
Running
- Description: 'Running' indicates that the experiment has been launched and data is actively being collected.
- Usage: This phase collects live data as users interact with the tested variations.
- Next Steps: Once enough data is collected to make an informed decision, shift the experiment to 'Ready for review.'
Ready for review
- Description: In 'Ready for review,' the experiment has finished collecting data and awaits detailed analysis. The experiment will transition to this state after your experiment end date passes.
- Usage: Use this phase to analyze the data, evaluate the performance of each variation, and understand the outcomes.
- Next Steps: Depending on the review, mark the experiment as 'Completed' or adjust and extend the 'Running' phase if needed.
Completed
- Description: A 'Completed' experiment has ended with a final decision made based on the collected data. You must click "Make decision" to transition the experiment to the "Completed" state.

- Usage: The completion phase documents the findings, shares results, and implements insights gained.
- Next Steps: Utilize the results for business decisions, make necessary changes, or develop new insights-based experiments.
Experiment duration and end-date
Each experiment requires you to set an end date. After that, the experiment state will change to "Ready for review."
Note that the progress bar shows the progress based on the end date defined.

Choosing an end date for your experiment
Selecting an experiment's end date is crucial to obtaining valid and actionable results. Here's a guide to help you choose an appropriate end date:
-
Statistical Significance
- Aim for a duration that allows enough data collection to achieve statistical significance.
- Your sample size should satisfy the power and minimum detectable effect (MDE) you've set.
-
Business Cycles
- Align your experiment's end-date with your business cycles to avoid confounding effects.
-
Seasonality
- Consider the potential impact of seasonality and aim to capture full business cycles.
-
Variation Performance
- If applying sequential testing, end the experiment once there's a statistically clear winner, respecting stopping rules.
-
Urgency of Implementation
- The need for quick results may influence your end-date but weigh this against the potential trade-off in data reliability.
Evaluating the experiment
Check out Experiment analyticsfor a complete overview of how to evaluate your experiment performance.
Calling a server-side experments
Rest API
In your code, use .choose() to request a variant of an experiment.
Path
https://api.intempt.com/v1/{orgName}/projects/{projectName}/optimization/choose-api
Parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
orgName | string | Yes | The name of the organization |
projectName | string | Yes | The name of the project |
identification | object | Yes | An object containing identifiers for the user |
-> sourceId | int64 | - | A unique identifier for the source |
-> profileId | string | - | A unique identifier for the user profile |
-> userId | string | - | A unique identifier for the user |
names | array of strings | Yes | An array of personalization or experiment selector names |
groups | array of strings | Yes | An array of personalizations or experiments that are grouped by the same group selector name |
device | string | No | The device used by the user. Possible values: all, mobile or desktop |
sessionId | string | No | A unique identifier for the session |
optimizationType | string | No | The type of optimization to be performed. It can be either a personalization or an experiment-type optimization. |
url | string | No | The URL to which the optimization is related |
Node.js and iOS SDKs
Intempt supports using Optimization APIs via our Node.js and iOS SDK libraries. Once initialized, these SDKs will allow you to use the Optimization APIs via simple methods.
The methods are explained in the Node.js SDK and iOS SDK documentation.
Updated 6 months ago