
Creating a likelihood model
Overview
Likelihood prediction allows you to build custom AI-powered models to predict any action you want to anticipate, for example:
- Predict future behavior
- Predict if a user will make a purchase
- Predict the likelihood of user churn
- Predict which visitors will subscribe
- Predict if users will subscribe to a specific plan
- Predict if subscribers will cancel subscription
- Predict which lapsed users will resubscribe
- Predict if users will download mobile app
- Predict which users will watch a series
- Predict if a user will contact an customer support rep
- Predict if current customers will open a new account
Intempt manages deployed models in batch or real-time using a predictive attribute made available after your model is trained and deployed. With just a few clicks, you can create segments by categorizing visitors based on model scores and target them with personalized experiences to drive ROI.
Good to know
This feature distills a complicated discipline (machine learning) into a fully managed feature. Intempt will process the data and output the model results with just a few clicks, without any developer or data scientist involvement required.
Prerequisites
Before creating the likelihood model, you must meet these criteria:
1. Data volume
- User volume minimums. Need at least 500 true and 500 false users (performed vs. not performed). The difference between true and false should be more than 1%.
- Dataset timeframe. Your dataset training timeframe must be at least the duration of the prediction window plus 1 additional day. For example, a “Likelihood to purchase in 30 days” model requires at least 31 days of data. For better training model accuracy, the training time frame should be 90 days regardless of the prediction timeframe selected in the UI.
2. Data quality
For optimal results, we suggest you have a high-quality dataset consisting of a clean data layer with a large amount of training data. Better data layer health allows you to create models that can provide immediate and meaningful prediction results.
Using the likelihood model
- Create the model. Select the target goal representing the visitor behavior you want to predict. The goal can be any event you select in the project.
- Train. After your target goal is ready for modeling, create a model and start training. While creating your model, an output attribute is created for you that will store prediction values for your model after you deploy it.
- Review. The AI model will output "Prediction quality" results indicating if the model is ready to be used in targeting.
- Create. After you are satisfied with the model's performance, you can target users using the likelihood attribute.
Creating the model
Go to Likelihood and select "Create model".
Choose the model type
Select the frequency of how model results are generated.
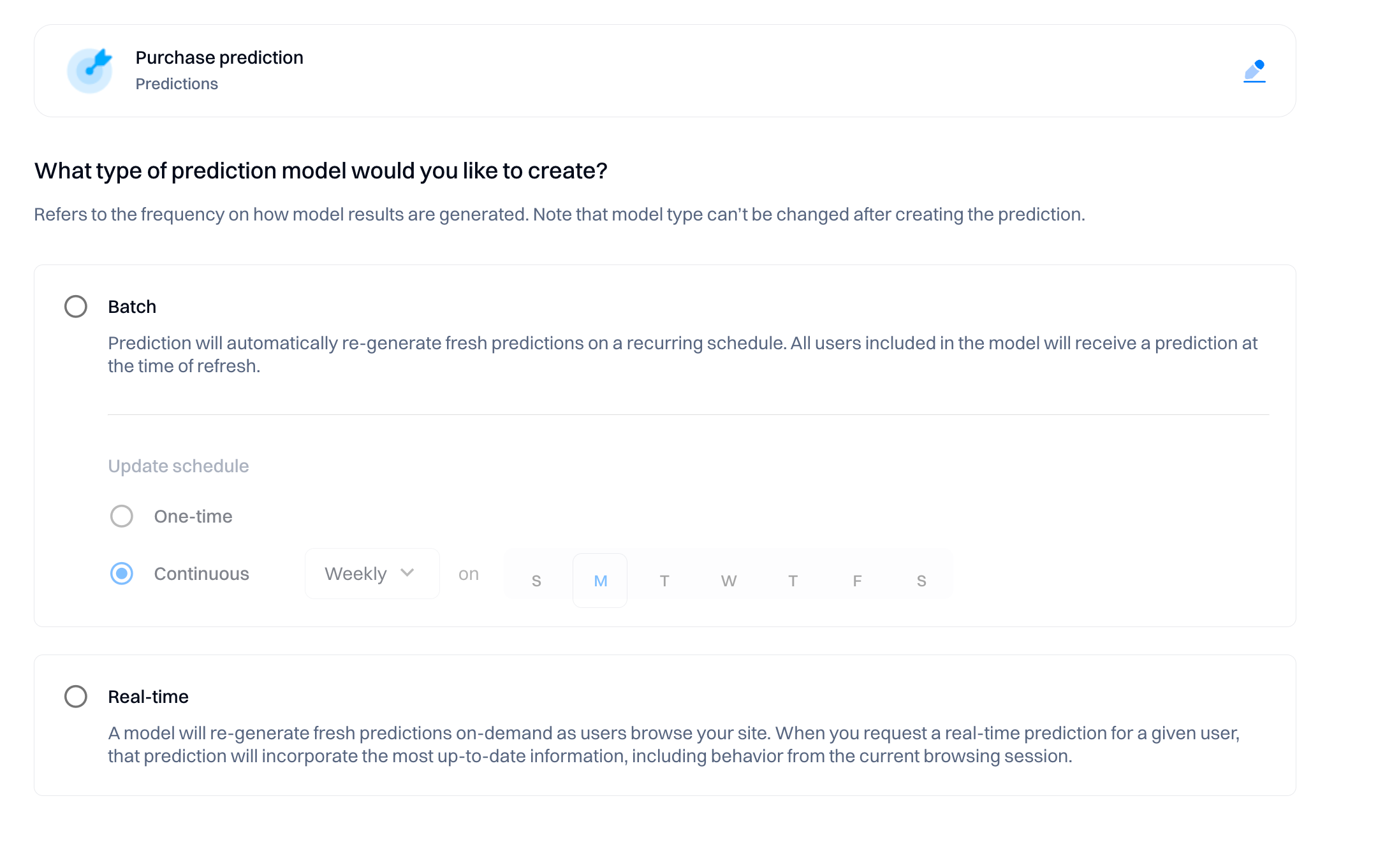
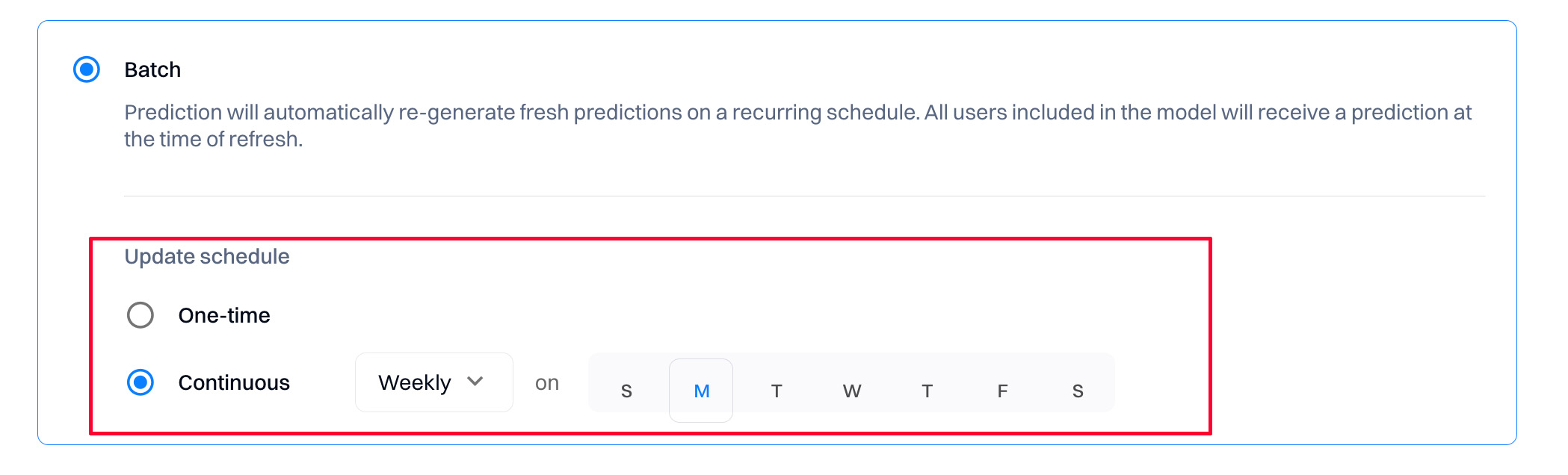
Batch model
Prediction will automatically re-generate fresh predictions on a recurring schedule. At the time of refresh, all users included in the model will receive a prediction.
You can specify how frequently the model will be updated:
- One-time. This option allows you to run the batch job only once. You would typically use this option if you want to execute the batch job immediately or at a specific time but do not need it to repeat.
- Continuous. This option allows you to schedule the batch job to run repeatedly. You can choose between daily or weekly intervals and select a specific day for the job to run. For example, if you select "Weekly," you can then choose which day(s) of the week the job should execute.
Real-time model
A model will re-generate fresh predictions on-demand as users browse your site. When you request a real-time prediction for a given user, that prediction will incorporate the most up-to-date information, including behavior from the current browsing session.
Batch vs. real-time
Whether or not you use batch or real-time inference depends on how you plan to deploy the model:
- For offline use cases, your model should make batch predictions. These predictions are generated simultaneously, so they can easily be refreshed in bulk on the same schedule.
- Online use cases (such as dynamic targeting on your website or app) can leverage either batch or real-time predictions. However, real-time predictions carry a few key advantages in this setting: (1) predictions are always up-to-date at the time they are used for decision-making, and (2) predictions can be made for first-time users.
| Batch | Real-time | |
|---|---|---|
| Pros | - Analyzes historical data for strategic decision-making | - Provides real-time insights for immediate action |
| - Suitable for large-scale analysis and segmentation | - Enables dynamic personalization and targeting | |
| - Enables long-term planning and forecasting | - Supports real-time fraud detection and prevention | |
| - Facilitates real-time response to dynamic changes in user behavior | ||
| Cons | - Requires periodic data updates and processing, leading to potential delays in decision-making | - May require significant computational resources and infrastructure to support real-time processing |
| - May not capture recent trends or changes in user behavior as effectively as real-time models | - Complexity increases with the need for real-time data integration and model deployment | |
| - Limited ability to respond to real-time events or changes in user behavior | - May be more susceptible to noisy or incomplete data due to the rapid pace of processing |
Choose the prediction goal
This refers to the event you want to predict whether the user will perform. Note that you can only select from events available in the project to define the goal.

"Within" refers to the time the predicted event should be performed. For example, if you choose the event "Purchase" and the 7-day time window, the model will predict if the user will perform the event in the next 7 days.
Select training timeframe
The training timeframe will determine within what period you will use the training data to create the model.
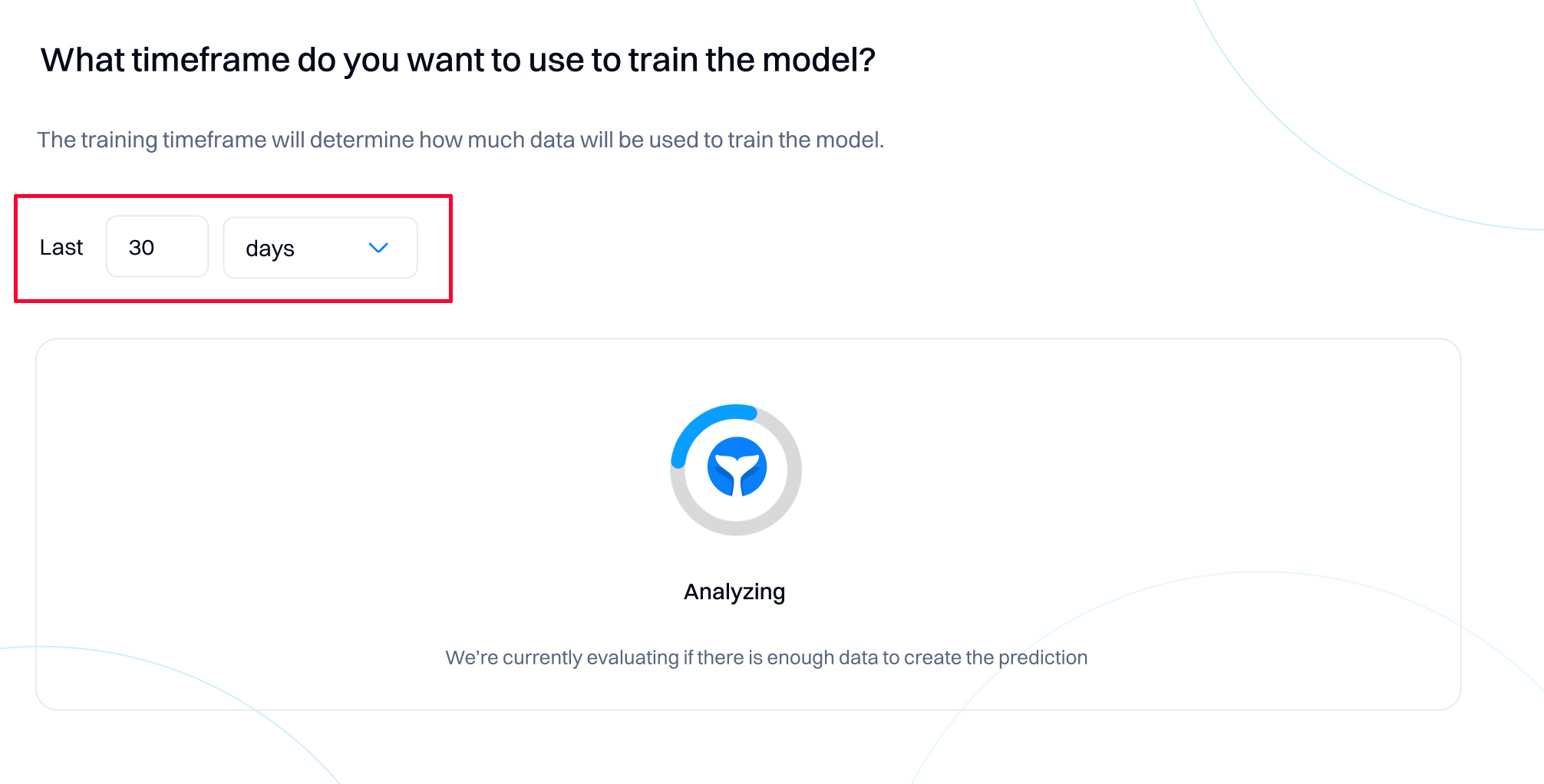
Consider these points when selecting the timeframe:
- Relevance of data. The data used to train the model should reflect the conditions under which the model will operate. If the training data is outdated, the model may not be able to accurately predict future events because the underlying patterns may have changed.
- Changing patterns. In many domains, patterns and trends change over time. For example, consumer preferences, market conditions, and even weather patterns can evolve. If the training data is too long, the model might capture outdated trends, negatively impacting its predictive performance.
- Seasonality.Some data exhibits seasonal patterns, such as retail sales peaking during holidays. By specifying a timeframe that captures the relevant seasonal patterns, you can help the model understand these fluctuations and improve its predictions accordingly.
- Data volume. The volume of data used for training can impact both the model's performance and the time it takes to train. By focusing on a specific timeframe, you can control the data used and prevent the model from being overwhelmed with unnecessary or redundant information.
- Model stability. If a prediction model is trained on data spanning an excessively broad timeframe, it might generalize poorly because it has encountered too many disparate patterns. A focused training timeframe helps build a stable and reliable model for the specific period you're interested in predicting.
- Performance Evaluation. When you specify a training timeframe, you also set a clear boundary for testing the model's performance on unseen data. This is vital for evaluating how well the model will perform in real-world scenarios.
Evaluate the readiness
After you select the timeframe, Intempt will evaluate if your goal event has enough data to create the model.
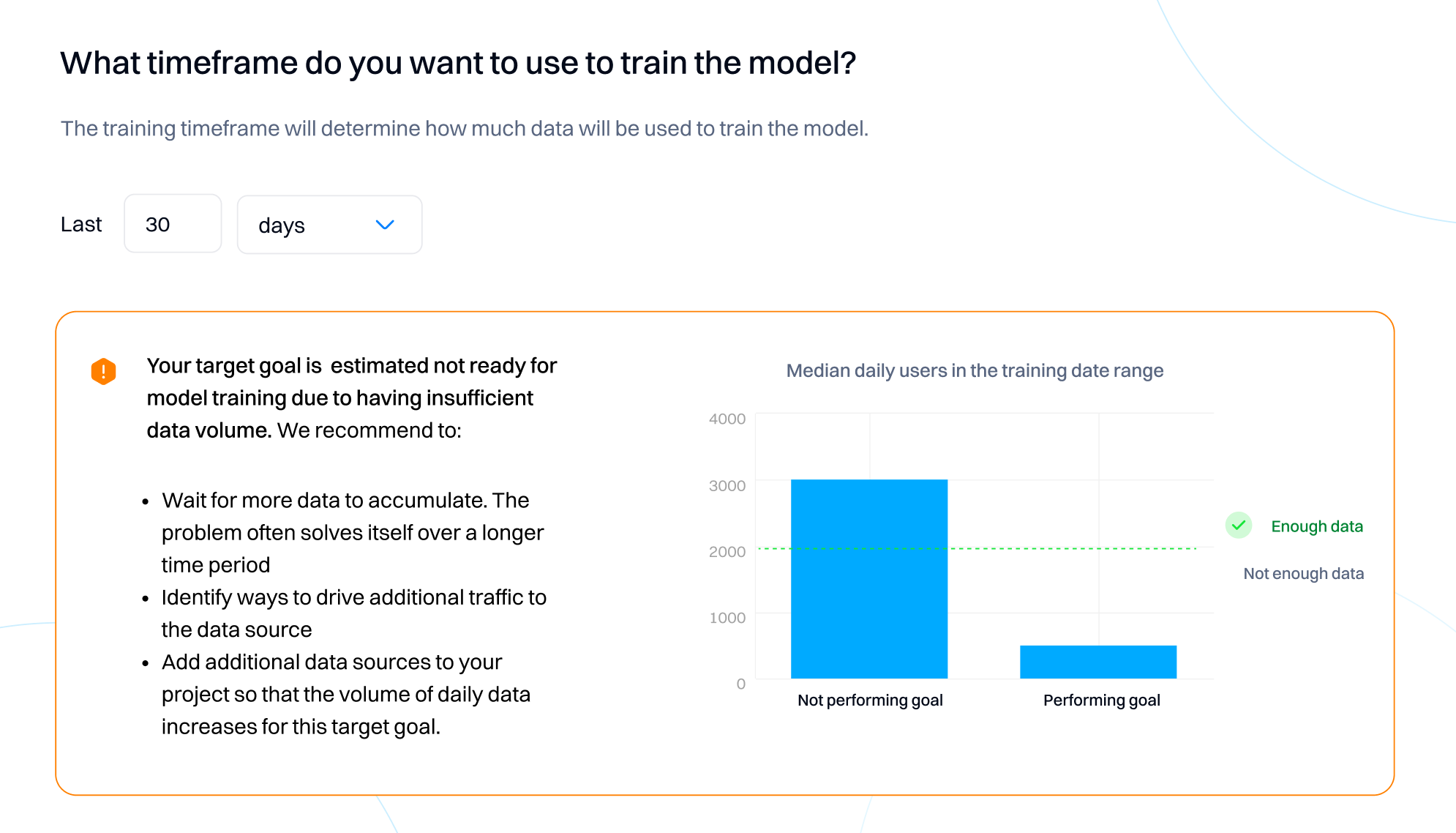
Depending on your dataset distribution, you will see labels "Not enough data" or "Enough data" for the number of users performing/not performing the goal event within the training timeframe.
Both the true and false groups must be above a minimum threshold. For example, for the training timeframe dates, the median daily counts of performing/not performing the event must be greater than or equal to 200. This threshold is intentionally set as low as possible to provide the most options possible for the goal event. A model with a goal event labeled "Not enough of data" typically fails during the training process due to insufficient data for the model.
A rating of "Not enough data" does not mean that the attribute is problematic in other contexts, but that it is currently deemed insufficient for successful training of a model.
If the goal you want to use is labeled as "Not enough data," try one of the following solutions:
- Wait for more data to accumulate. The problem often solves itself over a longer period. Identify ways to drive additional traffic to the data source.
- Add additional data sources to your project so that the volume of daily data increases for this goal.
Select which users should get the prediction scores
Depending on your use case, you can filter out users for whom you don't want to generate the predictions.
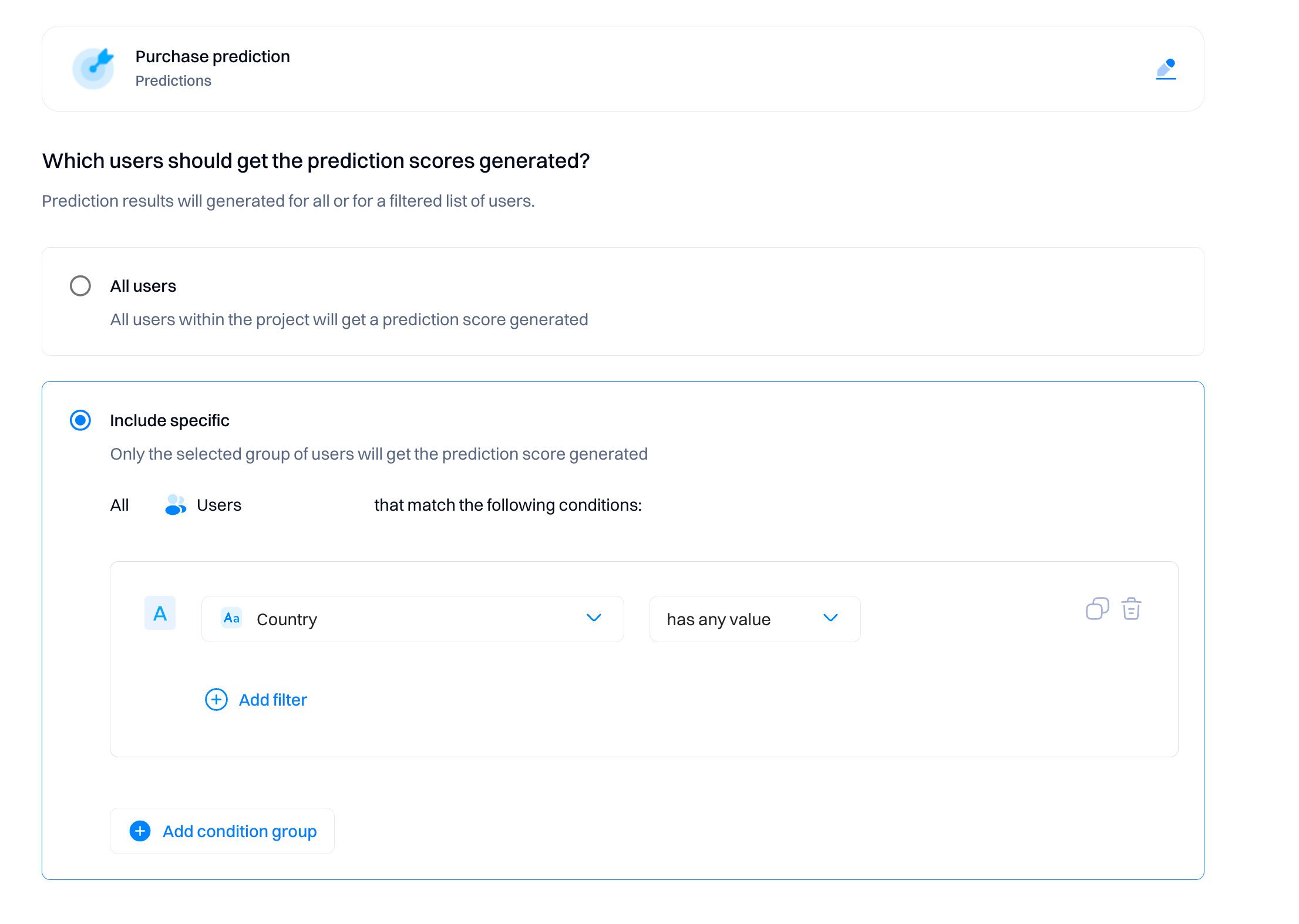
Consider these points when selecting the filter criteria:
- Relevance. Not all users may benefit from or need the predictive scores generated by a model. By filtering users based on relevant criteria, you ensure that only those likely to benefit from the predictions receive them. This helps prevent irrelevant or unnecessary information from being presented, leading to better user experiences and more targeted actions.
- Accuracy. Predictive models work best when applied to users who fit the criteria the model was designed for. If a model is designed to predict customer churn, for example, it may not be suitable for all customers equally. By filtering out users who do not meet specific criteria, you maintain the model's accuracy by focusing on the right subset of users.
- Resource optimization. Running predictive models can be resource-intensive in terms of computing power and time. Filtering out users who do not need predictive attribute scores can help you get faster prediction scores.
- Actionability. Predictive attribute scores are often used to guide specific actions, such as targeted marketing campaigns or personalized recommendations. Filtering out users who do not align with the goals of these actions ensures that resources are directed toward users who are more likely to respond positively, thereby enhancing the effectiveness of these initiatives.
- Privacy and compliance Some users may now be permitted to use their data for marketing purposes. In this case, to comply with the privacy regulations, they should be excluded from the score generation.
Managing the model
Go to Managing the prediction model to update the model configuration and review its results.
Updated 2 months ago